*왜 의료용 이미지에서 U-Net을 사용할까?
의료용이미지는 맥락이 중요하다 즉, 국소부분의 분할의 정확성보다 전체적인 영상에서의 분할이 중요하다. Ex) 암부위 분할
그러기 위해서 이미지의 특징을 국소적으로 패치방식으로 추출하면서도 고차원적인 정보를 skip-connection하여 위치 정보를 보완해주기때문에 비교적 정확한 위치로 국소부분을 분할할 수 있기때문이다.
*skip-connection이란?
디코더 부분에서 Upsampling시에 이전 인코더 부분의 Downsamping에서의 마지막 Layer의 Feature map을 넘겨받아 channel 방향으로 concatenation한다.

✅ UNet이란?
의료 이미지에서 많이 사용되는 이미지 세그멘테이션 알고리즘 중 하나이다.
그중에서도 semantic segmantaion에 해당된다.
*이미지 세그멘테이션: 이미지를 픽셀 단위로 분류
그중에서도 이미지 세그멘테이션은 semantic segmantaion과 Instance segmentaition으로 분류됨
*semantic segmantaion:이미지 내의 객체들을 의미있는 묶음으로 분할
*Instance segmentation:같은 카테고리내 서로다른 객체까지 분할하여 semantic segmantaion을 더 확장함 ex) 개1,개2,고양이
이미지 세그멘테이션은 의료 이미지 분석(종양경계추출), 자율주행차량(도로면, 보행자 감지) 및 증강현실과 같은 다양한 분야에서 사용됨
그중 의료용 이미지에는 U-Net이라는 알고리즘이 많이 사용됨
U-Net 논문을 보면 데이터셋이 30개로 굉장히 희박한데 그이유는 의료데이터가 의료보호법에 보호되고 있고 라벨링도 부족하기 때문이다.그럼에도 불구하고 높은 성능을 보였다.
✅ U-Net논문에서 특징
의료 데이터가 적기도 하고 너무 영상이 크기때문에 잘라서 데이터 수를 늘리려고 한다.
어떻게 가능할까?
↓
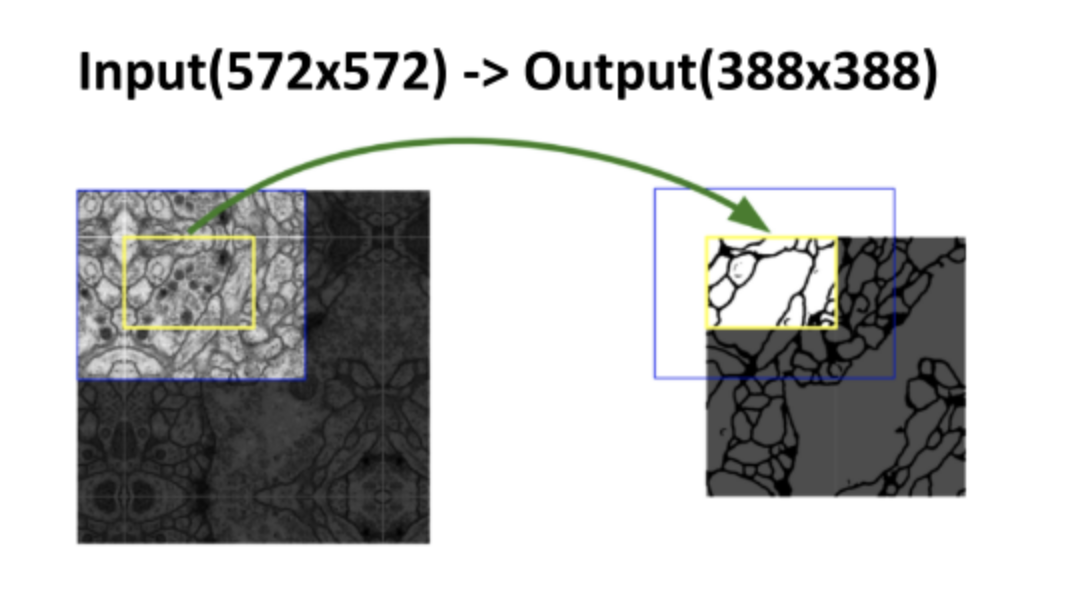
1️⃣ 전처리에서 패치탐색 방식인 Overlap-tile strategy를 사용했음
*기존에 슬라이딩 윈도우 방식을 안 쓴이유: 중복된 연산이 너무 많아져서 비효율적임
* Overlap-tile strategy: 패치 탐색 방법의 한 변형으로, 겹치는 부분을 통해 경계 정보의 손실을 줄이고 정확한 분할을 가능하게 함
출처: https://kuklife.tistory.com/119
padding_mode를 reflect로 하여 빈부분을 메꿀 수 있다. (파란색 부분)
특징을 추출하면서도 위치정보를 보존하게하려면 어떻게 해야할까
↓
2️⃣ skip-connection
*기존 FCN방식과 U-Net의 차이점?
스킵커넥션의 방식이 채널 방향으로 concatenation임 ( FCN방식은 SUM방식)
이를 통해 업샘플링의 특징을 다운샘플링에서 받아서 위치정보를 보존하므로 세밀한 경계 추출 가능
참고: segmentation과 비교해 보면 FCN은 skip-connection 사용 시 ResNet과 유사하게 sum 연산을 이용하는 반면 U-net은 DenseNet과 유사하게 concatenation 연산을 한다고 생각하시면 됩니다.
(출처: https://gaussian37.github.io/vision-segmentation-unet)
✅ Unet의 구조
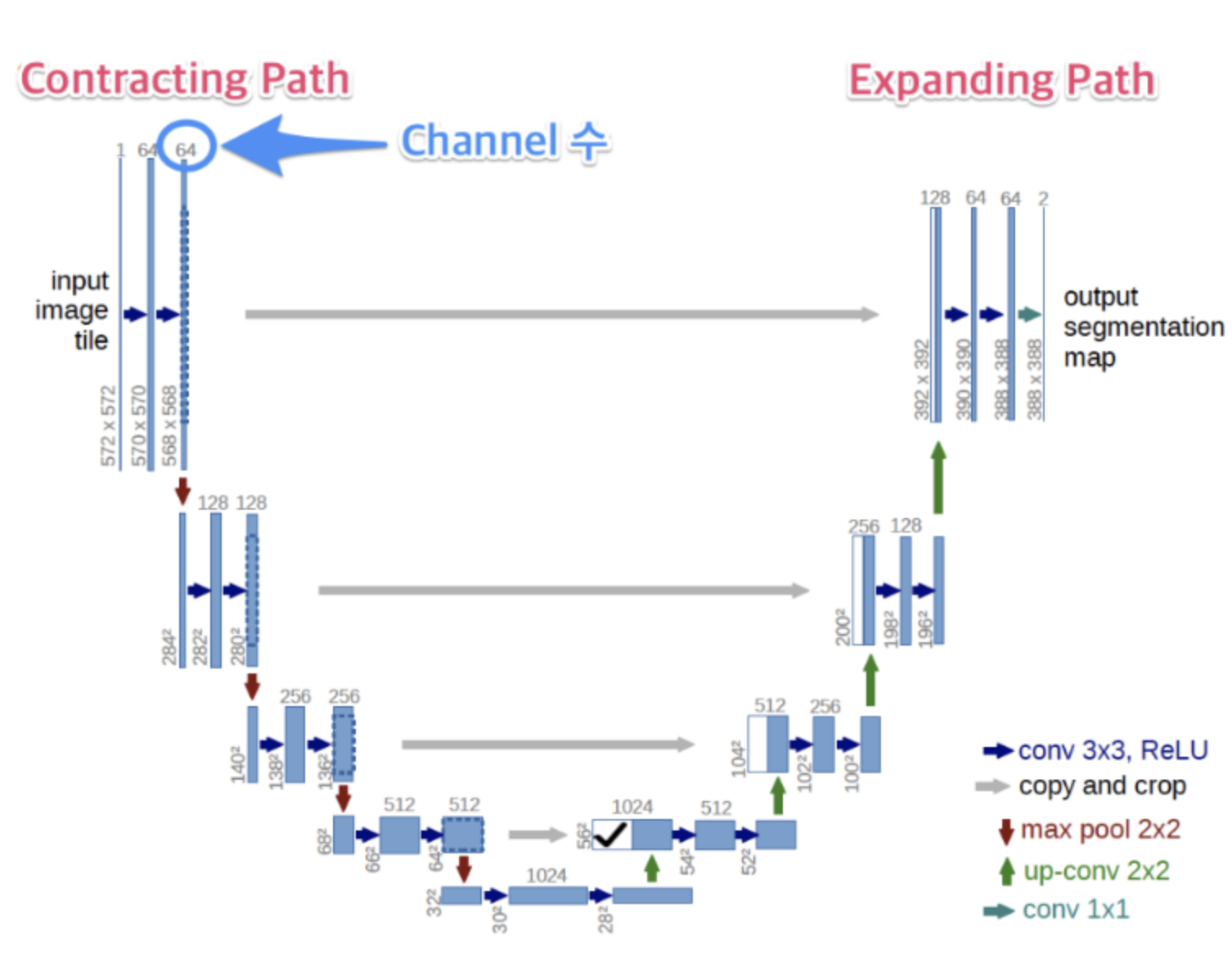
1️⃣ Unet의 입력과 출력 모습
마지막 결과 텐서가 (388,388,2)인데 채널이 2개인 이유는 각각 세포 경계선, 세포 내부인지에 대한 확률 값으로 구성됨
채널 2로 할 경우 각 채널에 대해 속할 확률을 출력하므로 두클래스 간 상대적인 확률을 좀더 세부적으로 학습할 수 있음
이를 이후 소프트맥스를 통해 총합을 1로 변환해서 각 클래스에 속할 확률을 계산할 수 있음
이를 채널 1로 해서 구할 경우 시그모이드함수를 활용하여 0~1사이 이진분할 값으로 해당 클래스에 속할 확률을 구할 수 있음
2️⃣ constracting path의 구조
3x3 convolution + BatchNorm2d +ReLU -> 2x2 max pooling 구조의 반복
■ convolution
1) 필터 개수 선정: convolution에서 초기 필터개수가 64개인 이유는? 경험적으로 가장 성능이 높아서
2) 필터 값(가중치) 갱신: 각 필터의 값인 가중치가 학습을 거듭하면서 역전파를 통해 특징을 더 잘 추출할수 있는 값으로 정해짐
3) 편차가 필요한 이유: 가중치 뿐만아니라 편차가 필요한이유는 활성화함수에서의 입력값이 0이되는 것을 막아주어 비선형 출력을 가능하게 해줌
■ BatchNorm2d: 컨볼루션 연산 후 배치 정규화를 하는 이유는? 입력값을 평균 0,분산 1로 만들어 추후 활성화함수에 적용시 학습에 안정감을 주기 위함
■ ReLU : 음수면 0, 양수면 해당값으로 변환하여 학습의 비선형성을 높임
비선형성이란? XOR 문제처럼 하나의 직선 즉, 선형적으로 표현될 수 없는 경우 복잡한 패턴을 학습하기 위해 비선형성 도입이 필요함
XOR 문제: 입력이 (0, 0) 또는 (1, 1)일 때 출력은 0 ,입력이 (0, 1) 또는 (1, 0)일 때 출력은 1
■ max pooling
1) 2x2 max pooling 한이유: 크기를 1/2로 줄여서 특징을 단순화하여 추출하기 취함
* 특징 단순화가 필요한이유: 오버피팅의 가능성이 있어서
2) 채널이 2배가 되는 이유: 필터가 그대신 2배가 됨. 즉, downsample 시 feature의 크기는 1/2배, channel의 수는 2배
3️⃣ expanding path의 구조
■ 3x3 convolution + ReLU
■ upsample 시 feature의 크기는 2배(2x2 up-convolution), channler의 수는 1/2배
■ copy and crop : contracting path의 feautre를 copy한 다음 그림에서와 같이 expanding path의 대칭되는 계층에 concatenation을 합니다. 이 때 contracting path와 expanding path의 feature 크기가 다르므로 contracting path의 feature를 copy한 다음 concatenation을 할 expanding path의 feature 사이즈에 맞추어서 crop을 합니다. 따라서 이 작업을 copy and crop이라고 합니다.
✅ 전체 코드
def ConvBlock(in_dim, out_dim, act_fn):
model = nn.Sequential(
nn.Conv2d(in_dim, out_dim, kernel_size = 3, stride = 1, padding = 1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def ConvTransBlock(in_dim, out_dim, act_fn):
model = nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size = 3, stride = 2, padding=1, output_padding = 1),
nn.BatchNorm2d(out_dim),
act_fn,
)
return model
def Maxpool():
pool = nn.MaxPool2d(kernel_size = 2, stride = 2, padding = 0)
return pool
def ConvBlock2X(in_dim, out_dim, act_fn):
model = nn.Sequential(
ConvBlock(in_dim, out_dim, act_fn),
ConvBlock(out_dim, out_dim, act_fn),
)
return model
class UNet(nn.Module):
def __init__(self, in_dim, out_dim, num_filter):
super(UNet, self).__init__()
self.in_dim = in_dim
self.out_dim = out_dim
self.num_filter = num_filter
act_fn = nn.LeakyReLU(0.2, inplace = True)
self.down_1 = ConvBlock2X(self.in_dim, self.num_filter, act_fn)
self.pool_1 = Maxpool()
self.down_2 = ConvBlock2X(self.num_filter, self.num_filter * 2, act_fn)
self.pool_2 = Maxpool()
self.down_3 = ConvBlock2X(self.num_filter * 2, self.num_filter * 4, act_fn)
self.pool_3 = Maxpool()
self.down_4 = ConvBlock2X(self.num_filter * 4, self.num_filter * 8, act_fn)
self.pool_4 = Maxpool()
self.bridge = ConvBlock2X(self.num_filter * 8, self.num_filter * 16, act_fn)
self.trans_1 = ConvTransBlock(self.num_filter * 16,self.num_filter * 8, act_fn)
self.up_1 = ConvBlock2X(self.num * 16, self.num_filter * 8, act_fn)
self.trans_2 = ConvTransBlock(self.num_filter * 8, self.num_filter * 4, act_fn)
self.up_2 = ConvBlock2X(self.num_filter * 8, self.num_filter * 4, act_fn)
self.trans_3 = ConvTransBlock(self.num_filter * 4, self.num_filter * 2, act_fn)
self.up_3 = ConvBlock2X(self.num_filter * 2, self.num_filter, act_fn)
self.trans_4 = ConvTransBlock(self.num_filter * 2, self.num_filter, act_fn)
self.up_4 = ConvBlock2X(self.num_filter *2, self.num_filter, act_fn)
self.out = nn.Sequential(
nn.Conv2d(self.num_filter, self.out_dim, 3, 1, 1),
nn.LeakyReLU(0.2, inplace = True),
)
def forward(self, input):
down_1 = self.down_1(input) # concat w/ trans_4
pool_1 = self.pool_1(down_1)
down_2 = self.down_2(pool_1) # concat w/ trans_3
pool_2 = self.pool_2(down_2)
down_3 = self.down_3(pool_2) # concat w/ trans_2
pool_3 = self.pool_3(down_3)
down_4 = self.down_4(pool_3) # concat w/ trans_1
pool_4 = self.pool_4(down_4)
bridge = self.bridge(pool_4)
trans_1 = self.trans_1(bridge)
concat_1 = torch.cat([trans_1, down_4], dim = 1)
up_1 = self.up_1(concat_1)
trans_2 = self.trans_1(up_1)
concat_2 = torch.cat([trans_2, down_3], dim = 1)
up_2 = self.up_1(concat_2)
trans_3 = self.trans_1(up_2)
concat_3 = torch.cat([trans_3, down_2], dim = 1)
up_3 = self.up_1(concat_3)
trans_4 = self.trans_1(up_3)
concat_4 = torch.cat([trans_4, down_1], dim = 1)
up_4 = self.up_1(concat_4)
out = self.out(up_4)
return out
'인공지능 > 이론' 카테고리의 다른 글
| [Segmentation 성능 측정 지표] IoU와 Dice Score의 차이 (0) | 2024.09.16 |
|---|